Harnessing Vectors and Contextual Retrieval in AI Pipelines
We used to search with words. Now we search with meaning.
In the old world of information retrieval — relational databases, inverted indexes, BM25 — text was chopped into tokens. You searched by matching those tokens, ranking by frequency and overlap.
It was fast and precise — but rigid.
Then came large language models. And they didn’t just read words — they understood them. They didn’t care whether a document used “car” or “automobile”, “boot error” or “startup issue”. They saw through the surface and mapped everything to vectors — floating-point fingerprints of thought.
And that changed everything.
Vectors aren’t just math. Vectors are the language of AI. They’re how machines “understand” and “retrieve” meaning.
This phrase was popularized by Swami Sivasubramanian at the AWS New York Summit 2025, where he unveiled Amazon S3’s native vector support — marking a pivotal shift in how AI systems handle unstructured data at scale.
🔁 From Keywords to Vectors: Why the Shift?
Let’s compare the two worlds:
Traditional Search
Vector (Semantic) Search
Tokens (words) indexed literally
Sentences embedded as vectors
Matches on exact words
Matches on meaning
Precise, but rigid
Flexible, but fuzzy
Cannot handle synonyms/paraphrases
Understands them well
Fast and explainable
Richer but less interpretable
So why move to vectors?
1. Vocabulary mismatch
Keyword search fails if the query and document use different words:
Query: “How to fix startup problems”
Doc: “Resolving boot errors”
Embeddings know these are close in meaning. Tokens don’t.
2. Long-form queries
People now ask full questions:
“What’s the safest way to invest for retirement at age 40?”
Classic search struggles here. Vector search thrives, mapping the whole intent of the query into semantic space.
3. Open-ended exploration
Semantic search is perfect for:
Customer support (“How do I get a refund?” → “Returns and exchange policy”)
Discovery (“Articles like this one” → content-based recommendations)
Retrieval-Augmented Generation (RAG) — where you want the model to reason over related passages, not just exact matches.
🔢 Why Do Vectors Work So Well?
Modern language models are trained on massive corpora. When they generate embeddings, they don’t just look at individual words — they look at context.
“Apple” near “fruit” → food vector
“Apple” near “iOS update” → tech vector
This contextual disambiguation is why vector search outperforms keyword search in messy, real-world queries. It also enables cross-lingual search, multi-modal embeddings (text + image), and intent-based retrieval.
This shift — from matching tokens to mapping semantics — is what powers modern RAG systems. And while vectors were a leap forward, they weren’t enough. Because as it turns out, even AI can forget where a sentence came from.
🔍 What Is RAG, Really?
RAG (Retrieval-Augmented Generation) is one of those AI terms that sounds more intimidating than it is. Strip away the jargon, and here’s the simple idea:
Large Language Models are smart, but they forget things. RAG lets them go look it up.
When you ask a normal LLM a question, it has to answer based on what’s in its training data. But what if the answer is in your company’s knowledge base? Or your product docs? Or a new research paper it’s never seen?
That’s where RAG comes in.
The flow is simple:
Take the user’s query
Search an external knowledge source for relevant context
Feed that context — plus the original question — into the LLM
Let the model generate a grounded, helpful response
RAG doesn’t change how the model works. It just adds context before generation.
Think of it like this: you’re asking the model to write an essay, but before it starts, you hand it a few pages from a textbook. You don’t trust it to memorize everything — you want it to reason over what’s in front of it, in real time.
And that’s what makes RAG powerful. It’s the bridge between static language models and dynamic, up-to-date knowledge.
But here’s the twist:
If the retrieval step fails, everything downstream breaks.
The quality of your generation is only as good as what you retrieved. If the LLM never sees the answer, it can’t give you one.
Which brings us to the next frontier: making retrieval smarter.
That’s where contextual retrieval and contextual embeddings enter the picture.
Traditional RAG pipelines took a brute-force approach:
Chunk the documents
Embed the chunks
Search the vector database for nearest neighbors
It worked — until it didn’t.
Because when you split a document into pieces, something critical gets lost: context.
A chunk that says “The revenue grew 3% over the previous quarter” means nothing on its own. Which company? Which quarter? What industry?
Naive chunking treats every passage like it exists in isolation. But real-world information is connected. Meaning doesn’t live in a sentence — it lives in the structure around it: the title, the section, the speaker, the timeline.
This is where contextual retrieval comes in.
📎 The Fix: Give Chunks Their Memory Back
Contextual retrieval solves this by injecting context back into the chunk before embedding it.
Instead of embedding this:
“The revenue grew 3% over the previous quarter.”
We embed this:
“From ACME Corp’s Q2 2023 earnings call: The revenue grew 3% over the previous quarter.”
That little prefix? It’s everything.
By generating a chunk-specific context summary, we ground the passage in its original frame — who, what, where, when — so it becomes retrievable for queries that care about those details.
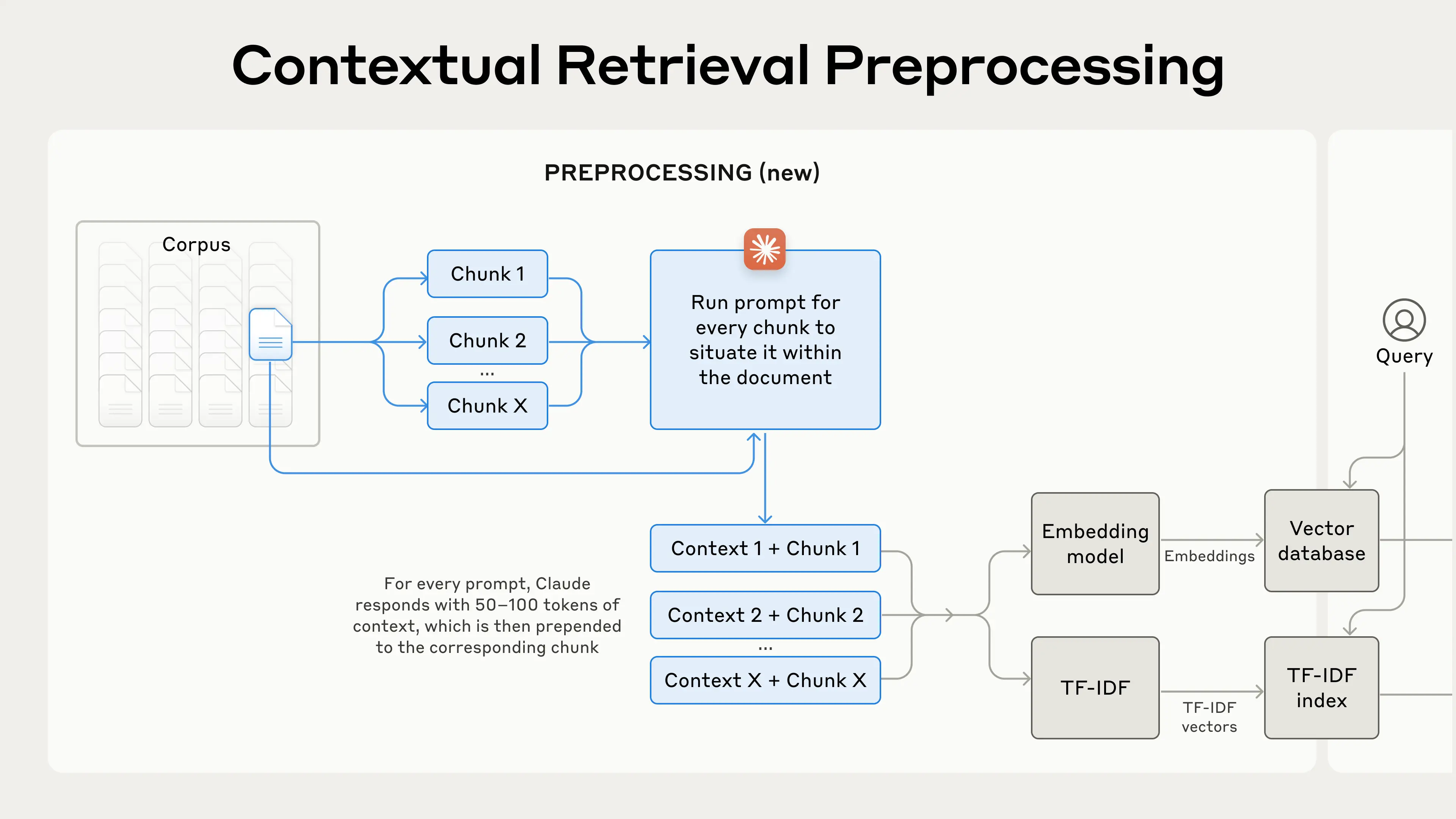
⚙️ How It Works
The contextual retrieval pipeline looks like this:
Document Preprocessing
Break into chunks (e.g. 300–500 tokens)
Use an LLM to generate a short summary of the chunk’s surrounding context
Contextual Chunk Construction
Prepend the summary to each chunk
E.g., “This is from a Google internal engineering blog, 2022…”
Embedding + Indexing
Embed the enriched chunk, not the raw text
Store in vector DB (and optionally BM25 for hybrid search)
Query Time
Convert the user query into an embedding
Retrieve top chunks — now enriched with metadata, making them far more matchable
Feed them to the LLM as grounding context for generation
📈 Why It Matters
In Anthropic’s benchmarks, contextual retrieval cut retrieval failures in half compared to standard RAG. With reranking on top, the failure rate dropped by 67%.
It also works model-agnostically — you can use OpenAI, Cohere, or any encoder.
What makes it powerful is that it doesn’t change how search works — it changes what you search on.
You don’t need smarter models. You need smarter chunks.
🧬 Evolving Techniques in RAG
Contextual Retrieval is just the start. RAG is evolving rapidly:
RAG is no longer a one-shot search — it’s an orchestrated pipeline of retrieval, filtering, ranking, and grounding.
🔎 Real-World Use Case: Smarter Library Search
Let’s take something familiar: public library search. Most systems — including my local Howard County Library — still rely on keyword-based search.
Imagine a parent looking for:
“Books for a curious 11-year-old boy who loves sharks, volcanoes, and old-fashioned adventure stories like Treasure Island or Hatchet.”
Good luck typing that into a keyword box.
Contextual retrieval would:
Understand the query’s intent
Match thematically aligned books even without shared keywords
Pull from book descriptions, reviews, even author interviews
And explain itself:
“This book is a good fit because it explores volcanoes through the eyes of a young protagonist.”
🛡️ Use Case: Internal Private Search (LocalGPT)
Organizations with sensitive data — legal memos, medical SOPs, engineering designs — often need AI search. But not cloud-based.
Enter LocalGPT.
Using open-source RAG stacks like LocalGPT, orgs can:
Store everything on-prem
Enrich PDFs, wikis, and docs with contextual embeddings
Use local LLMs (e.g. Mistral, llama.cpp)
Build private chat interfaces with no data leakage
Contextual retrieval lets you talk to your documents — without them ever leaving your walls.
🌍 More Real-World Use Cases Transformed by Contextual Retrieval
🏛️ Legal Discovery & Case Research
Find precedents even if phrased differently
Surface similar legal clauses
Ask: “Show me breach of contract cases in Maryland with similar clauses to this NDA.”
🏥 Clinical Notes & EHRs
Doctors can query with natural symptoms
Retrieve relevant patient notes even with varied phrasing
Boosts diagnosis, research, and personalized treatment
🏢 Enterprise Documentation Assistants
Ask: “Who owns deployment of system Y?”
Search across Confluence, Slack, GitHub
Always up-to-date, grounded in trusted sources
📦 Customer Service
Suggest policies and resolutions based on queries
Train bots to reply with context-backed precision
Less scripting, more relevance
🧾 Final Thoughts
Contextual retrieval isn’t just a better search engine. It’s a new cognitive layer for how machines understand meaning.
Where traditional search relied on matching words, RAG powered by contextual embeddings and retrieval bridges the gap between raw data and real insight.
In a world of hallucinations, the AI that retrieves the truth — wins.



Leave a comment