How Energy, Memory, and Compute Are Converging Into the New Industrial Revolution
AI is often described as “software,” but that framing hides the most important truth about this moment: modern AI behaves like an industrial system, not a digital product. Intelligence is no longer compiled once and distributed cheaply forever. It is manufactured continuously, in real time, using enormous amounts of electricity, silicon, memory, and physical infrastructure.
The scale of this build-out is staggering. Companies are investing hundreds of billions in new data center capacity, with some estimates suggesting the AI infrastructure market will exceed $500 billion annually by 2030. This represents the largest infrastructure expansion since the internet’s emergence in the 1990s.
What looks like an unprecedented global build-out of data centers, chips, and power generation is not speculative excess (Reuters, Dec 2025). It is the physical substrate required to sustain intelligence as a service.
To understand why this infrastructure boom is happening and why it is accelerating, we have to follow AI end-to-end: from energy, to silicon, to memory, to models, to inference. Only then does the scale make sense.
From Software to Industry
Traditional software has a simple cost structure. Engineers write code, compile it, and distribute it. The marginal cost of use is nearly zero. A spreadsheet application written decades ago still runs today with minimal additional infrastructure.
AI breaks that model entirely.
As Jensen Huang, CEO of NVIDIA, has repeatedly emphasized, AI is generated, not replayed. Every prompt produces new tokens. Every response requires live computation. Every interaction consumes power, memory, and bandwidth at the moment of use.
AI is software – but it’s not pre-recorded software.
In that sense, AI behaves less like software and more like electricity or manufacturing. Intelligence is produced on demand, continuously, at scale. Huang calls these systems AI factories, and the analogy is precise. These factories take energy as input and output tokens, decisions, simulations, and actions that are consumed across every industry.
Once you accept that framing, the infrastructure build-out stops looking optional.
Energy: The Raw Material of Intelligence
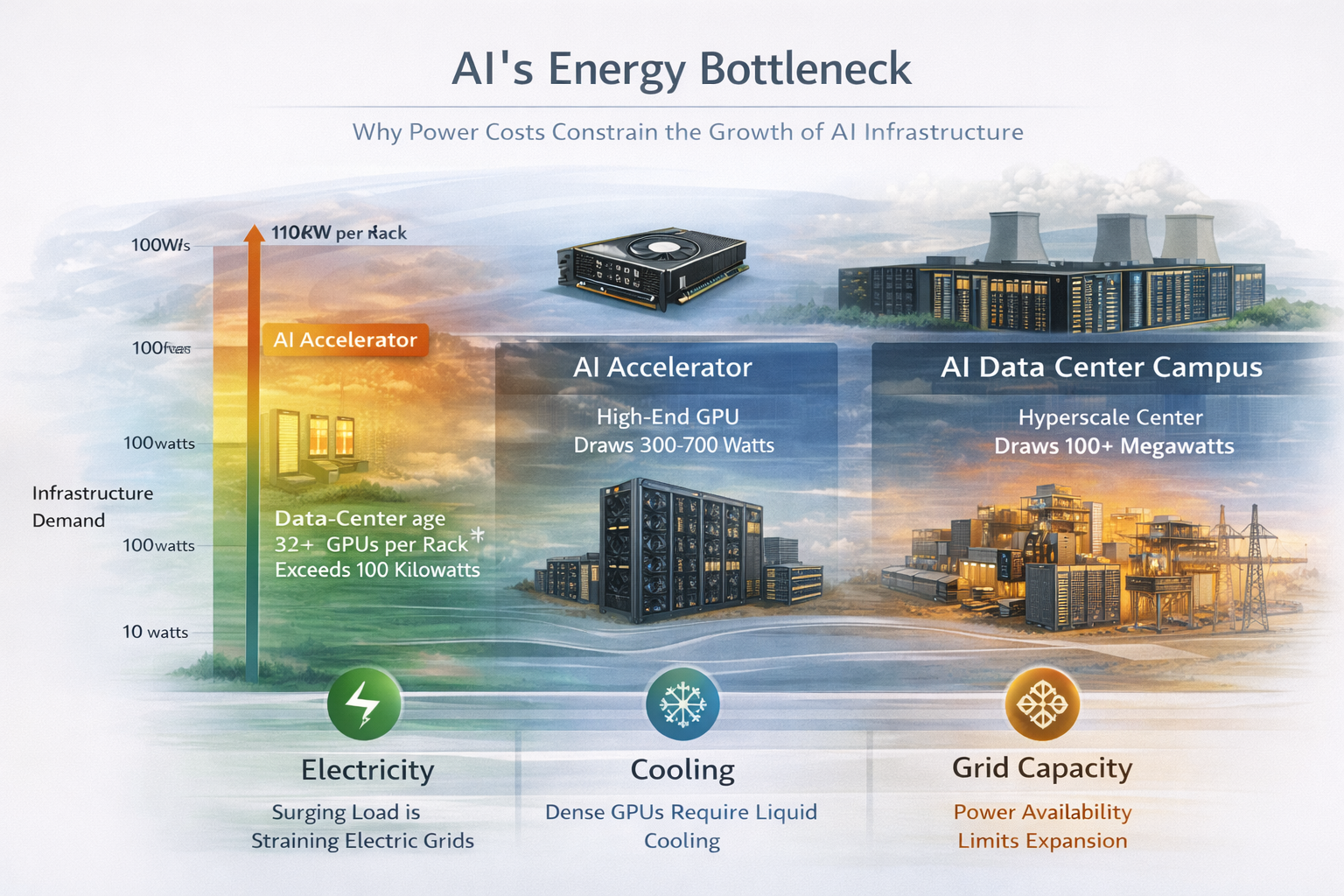
At the base of the AI stack is energy. Modern AI workloads run continuously at high utilization, unlike traditional enterprise servers that idle much of the time. A single high-end GPU can draw hundreds of watts; a rack can exceed 100 kilowatts; a data-center campus can rival a small city in electricity demand.
To put this in perspective: a single large AI data center can consume 500+ megawatts of electricity continuously. That’s equivalent to supplying power to a city of 500,000 people.
This is why AI infrastructure discussions have converged so quickly on power availability. GPUs do not merely use electricity, they convert it directly into intelligence. Every token generated is the result of thousands to millions of floating-point operations powered by electrons flowing through silicon.
Cooling compounds the problem. Dense GPU clusters require liquid cooling, redundant power delivery, and sophisticated thermal management. Even marginal efficiency gains matter when facilities operate at tens or hundreds of megawatts. This is why AI infrastructure is now tightly coupled with grid planning, energy contracts, and, increasingly, dedicated power generation.
Energy is not overhead. It is the first input in the AI production pipeline.
GPUs and FLOPs: Why Accelerated Computing Won
The next layer up is compute, and specifically accelerated computing. AI workloads are dominated by dense linear algebra,matrix multiplications repeated at enormous scale. CPUs, optimized for control flow and sequential execution, are poorly suited for this task.
GPUs, by contrast, were designed for massive parallelism. Thousands of cores execute the same operation across large tensors simultaneously. Specialized units,tensor cores,accelerate the multiply-accumulate operations that dominate neural networks.
This brings us to a key technical term: FLOPs.
FLOPs (floating-point operations per second) measure how many arithmetic operations a processor can perform. AI systems operate at teraFLOP, petaFLOP, and now exaFLOP scales. But FLOPs alone are misleading. A processor can advertise enormous compute capability and still underperform if it cannot be fed with data fast enough.
This is where the infrastructure story deepens.
Infrastructure: Turning GPUs Into a Single Machine
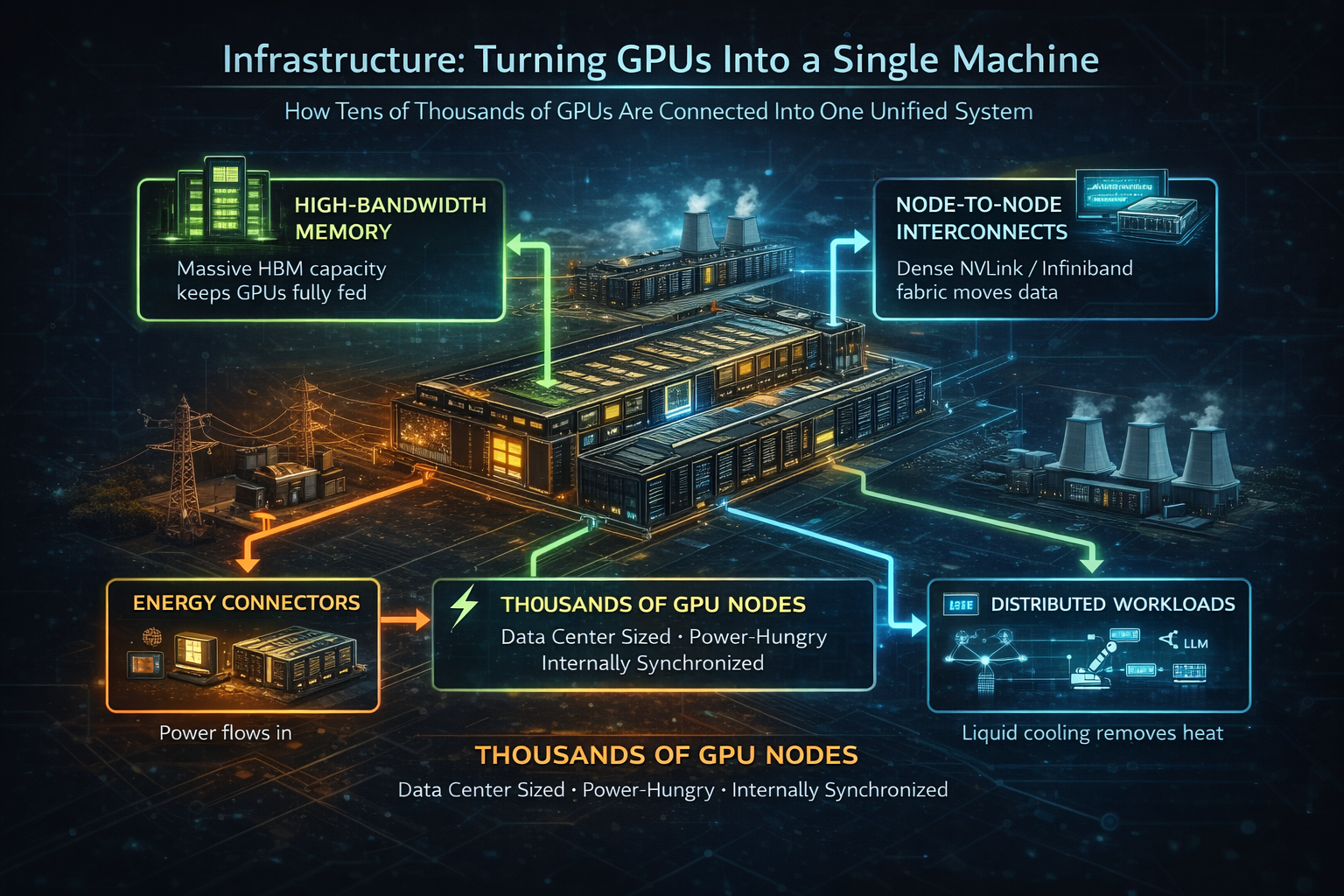
A single GPU is not useful for frontier AI. Modern models require clusters of thousands or tens of thousands of accelerators working in concert. That transforms the problem from chip design into systems engineering.
AI infrastructure must solve:
- High-bandwidth GPU-to-GPU communication
- Synchronization across distributed systems
- Fault tolerance at massive scale
- Predictable latency for inference
- High utilization to justify capital costs
Each of these challenges is formidable on its own. GPU-to-GPU communication bandwidth must scale with the number of GPUs; a cluster of 16,000 H100s requires interconnect bandwidth measured in petabits per second, exceeding the capacity of traditional networking. Synchronization means all GPUs must wait for the slowest unit before proceeding; a single point of failure cascades across thousands of chips. For perspective: enterprise supercomputers of the past cost hundreds of millions. Today’s AI clusters cost billions, and downtime, even brief represents catastrophic financial loss. The infrastructure must achieve unprecedented reliability while operating at the edge of physical and thermal limits.
These requirements explain why AI data centers resemble supercomputers more than traditional cloud facilities. Networking, interconnects, and orchestration become as important as raw compute. Underutilized GPUs still consume power and capital; efficiency is existential.
This is why the AI build-out is happening at the data-center level, not just at the chip level.
From Generative AI to Agentic and Physical AI
The next phase of AI growth is not simply about larger language models. It is about how models are used.

AI systems are evolving from generative models that respond to prompts into agentic systems that plan, reason, and act continuously, and ultimately into physical AI systems that operate in the real world (NVIDIA Blog, 2025).
This transition fundamentally changes infrastructure demand.
Generative AI workloads are bursty: a prompt arrives, tokens are generated, and computation stops. Agentic AI by contrast, keeps models active over long horizons. Agents maintain state, invoke tools, observe outcomes, and loop continuously. Physical AI extends this further by grounding intelligence in perception and action , vision, motion, force, and feedback , all running in real time.
In NVIDIA’s framing, this creates a clear progression:
- Generative AI produces content
- Agentic AI produces decisions
- Physical AI produces actions
Each step dramatically increases the need for persistent inference, long-lived memory, and tight coupling between compute and the physical world.
Why Agentic and Physical AI Explode Infrastructure Demand
Agentic and physical AI systems stress infrastructure in ways traditional inference does not.
Instead of short, stateless requests, these systems require:
- Continuous model execution
- Long context windows and memory retention
- Repeated state updates and feedback loops
- Real-time interaction with external systems and environments
These workloads increasingly resemble industrial control systems rather than traditional software services. GPUs are no longer accelerating isolated tasks; they are running always-on intelligence pipelines that combine simulation, reasoning, and action.
This directly amplifies demand for:
- High-bandwidth memory (to maintain state and context)
- Low-latency interconnects (to coordinate across agents and sensors)
- Power-dense infrastructure capable of sustained utilization
In effect, agentic and physical AI turn inference into a continuous manufacturing process, not a transactional service.
As AI expands beyond chatbots into robotics, autonomous vehicles, scientific simulation, and digital biology, inference becomes always-on and mission-critical. This dramatically increases infrastructure demand.
Memory: The Real Bottleneck
As compute capacity has exploded, a new constraint has emerged: memory.
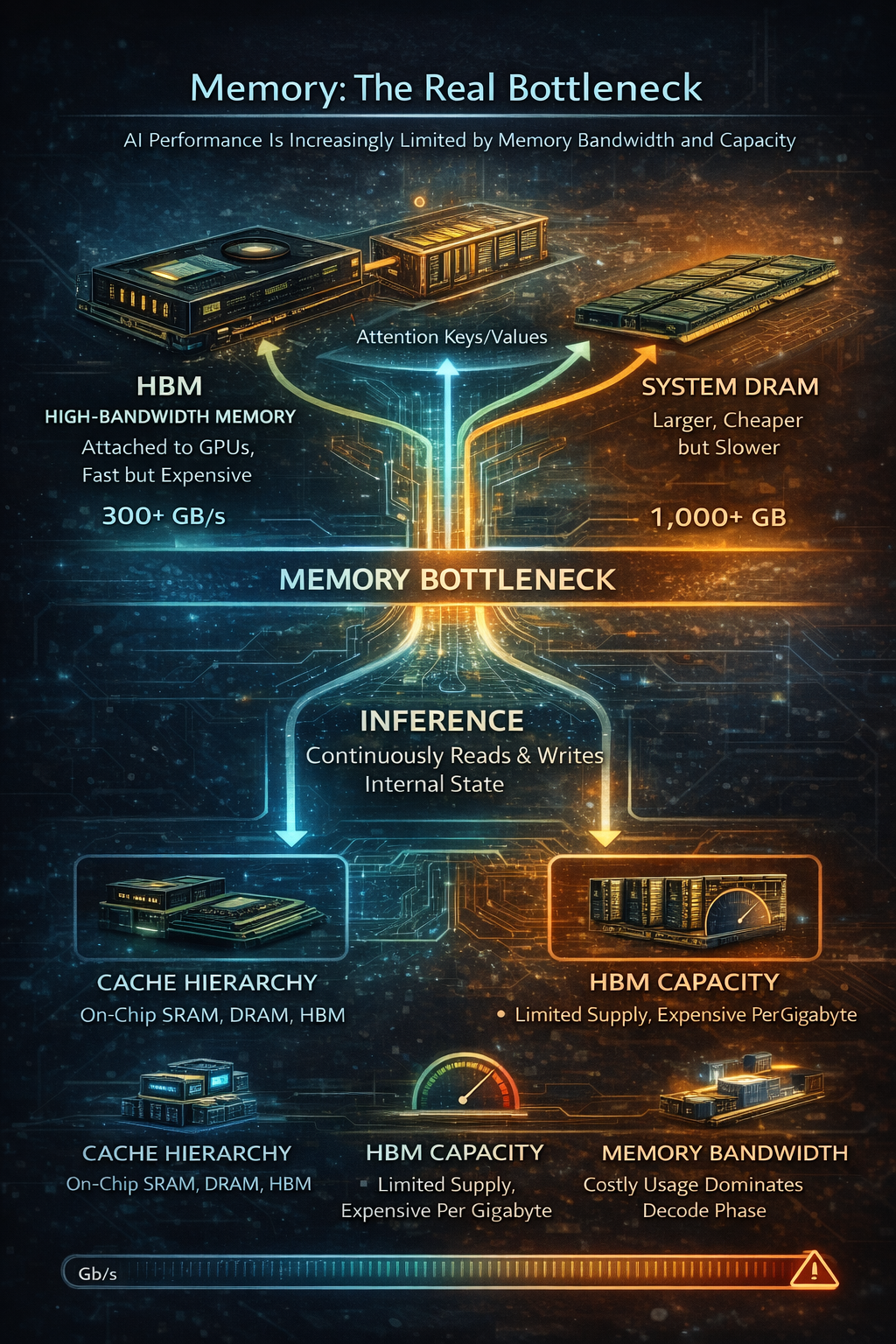
AI performance is increasingly limited not by how fast a chip can compute, but by how fast it can move data. Accessing memory consumes energy, introduces latency, and throttles throughput. During inference, models repeatedly read and write large internal state, especially attention caches.
Modern AI systems rely on a layered memory hierarchy:
- On-chip SRAM and caches for the hottest data
- High-Bandwidth Memory (HBM) tightly coupled to GPUs
- System DRAM for staging and orchestration
- Storage for checkpoints and datasets
Among these, HBM has become strategic. It delivers enormous bandwidth, but it is expensive, difficult to manufacture, and tightly supply-constrained. This is why memory, especially DRAM and HBM has emerged as a first-order bottleneck across the AI ecosystem.
Huang has been explicit about this: AI growth requires capacity of DRAM. Without memory, GPUs stall. Without GPUs, factories sit idle. Memory shortages ripple upward through the entire stack.
Recent news stories highlighting the shortages
- 🔗 Samsung warns of memory shortages driving industry-wide price surge in 2026 — Network World (Network World)
- 🔗 Memory chipmakers rise as global supply shortage whets investor appetite — Reuters (Reuters)
- 🔗 Smartphone and PC prices set to rise as AI boom drains memory chips — Financial Times (Financial Times)
- 🔗 Understanding the 2025 DRAM Shortage and Its Impact on Cloud Infrastructure Costs — SoftwareSeni (SoftwareSeni)
Prefill and Decode: Why Inference Is So Demanding
The runtime behavior of AI models explains why memory matters so much.
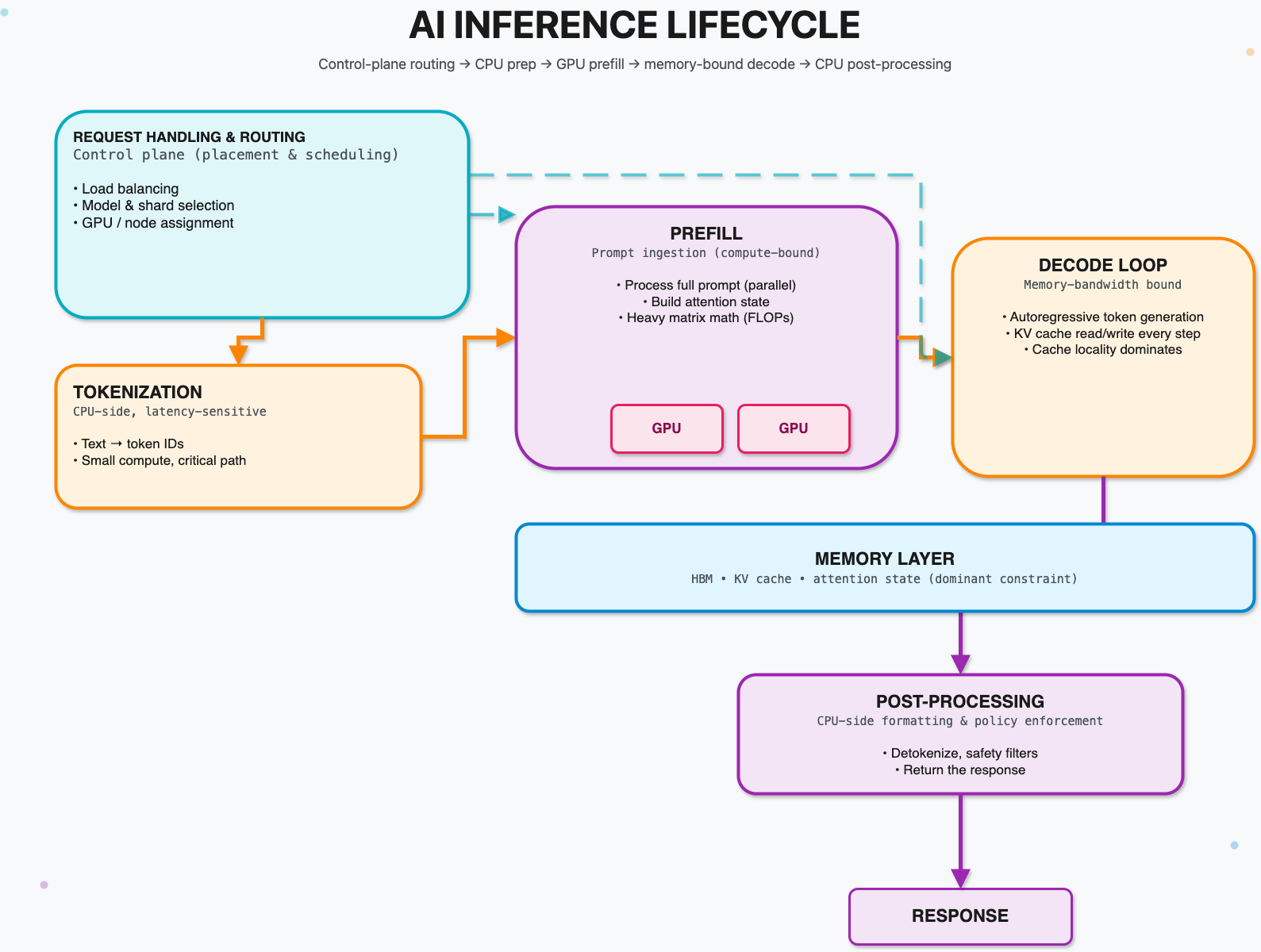
Inference has two distinct phases:
Prefill is the “reading” phase. The model ingests the entire prompt and builds internal representations. This phase is highly parallel and largely compute-bound. GPUs excel here.
Decode is the “writing” phase. The model generates output token by token. Each new token requires accessing and updating previously computed state so the model remains coherent. This phase is sequential and heavily memory-bandwidth-bound.
As context windows grow longer and applications become more interactive, decode dominates total inference cost. This is why architectures are shifting toward larger caches, more HBM, and designs that minimize data movement. Compute alone is no longer sufficient.
The Paradox: Falling Costs, Rising Investment
One of the most counterintuitive aspects of this moment is that AI costs are collapsing even as infrastructure spending explodes.

According to Huang, the cost per million tokens for GPT-4-class models has dropped by over 100× since 2020. Architectural improvements from Volta to Ampere to Hopper to Blackwell compound year over year. Each generation delivers 5–10× gains through better compute density, memory bandwidth, and efficiency.
As a result, tasks that once required billion-dollar supercomputers can now be done on a workstation, or even a high-end PC.
So why build more infrastructure?
Because efficiency increases usage. Cheaper intelligence enables more applications, longer contexts, higher concurrency, and always-on systems. Total demand rises faster than unit costs fall. This is the same dynamic that drove the expansion of electricity, bandwidth, and cloud computing.
AI infrastructure is not expensive because AI is inefficient. It is expensive because intelligence has become cheap enough to be used everywhere.
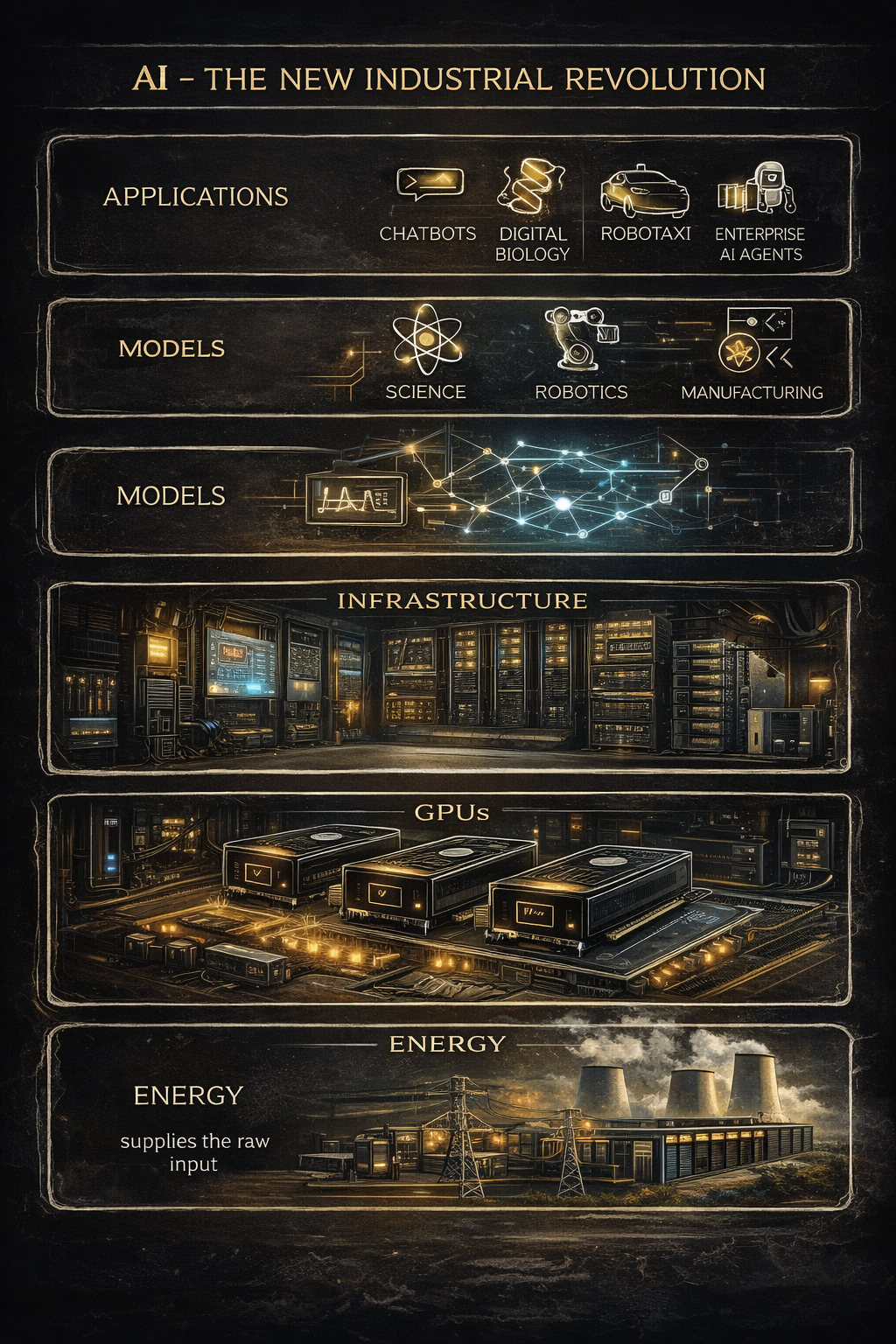
The New Industrial Stack
Taken together, the AI infrastructure stack looks unmistakably industrial:
- Energy supplies the raw input
- GPUs convert electrons into FLOPs
- Infrastructure turns chips into factories
- Models convert math into capability
- Memory sustains continuous inference
- Applications monetize intelligence at scale
The AI infrastructure boom is not speculative exuberance. It is what happens when intelligence becomes a real-time, compute-backed service embedded into every industry. Rather than focusing purely on model architectures or algorithms, the real bottleneck is increasingly physical: energy, power delivery, cooling, and chip connectivity.
Once tokens must be generated live, once models must reason continuously, once systems must perceive and act in the physical world, infrastructure becomes destiny. Power plants, chip fabs, data centers, memory supply chains, and skilled labor all become part of the AI stack. This is why major investments in data center infrastructure, power generation, and semiconductor manufacturing represent not exuberance, but rational planning for a fundamentally transformed technological landscape.
AI is no longer just software.
It is the newest industrial revolution, built in concrete, steel, silicon, and electricity.

Leave a comment