
“MLOps isn’t just a process—it’s a philosophy of continuous learning and governance across the entire model lifecycle.”
In this guide, I explore how modern MLOps architectures evolve from experimentation to enterprise scale, blending the rigor of DevOps, the agility of DataOps, and the governance of AI Risk Management Frameworks.
We’ll progressively zoom in—from the Model Development Lifecycle (MDLC) to concrete reference architectures on AWS, open-source stacks, and hybrid GenAI systems.
🧩 Part 1 — Understanding the Model Development Lifecycle (MDLC)
“Every machine learning model has a life. MLOps ensures it’s a long, healthy, and traceable one.”
What is MLOps and Why It Matters
Machine Learning Operations (MLOps) is the discipline of unifying data science, machine learning engineering, and DevOps to manage the entire lifecycle of an ML model—from ideation to retirement.
It ensures that models are repeatable, scalable, and governable across development and production environments.
As AWS defines MLOps, it is “a set of best practices that help organizations reliably and efficiently build, deploy, monitor, and maintain machine learning models in production.”
The goal is to bridge the gap between experimentation and enterprise deployment by automating the most fragile parts of the process: training, testing, deployment, monitoring, and retraining.
Unlike traditional DevOps, where the product (software) behavior is deterministic, MLOps deals with data-dependent behavior—models evolve as data changes. This introduces new operational challenges such as concept drift, data quality assurance, and ethical compliance.
In short, if DevOps is about shipping code safely, MLOps is about shipping learning systems safely.
MLOps integrates software engineering principles with the data-science lifecycle. It aims to automate and standardize how we build, test, deploy, and monitor ML models.
Phases of the Model Development Lifecycle (MDLC)
Every ML journey passes through six iterative phases. Each phase contributes artifacts, metadata, and governance checkpoints that feed the next.
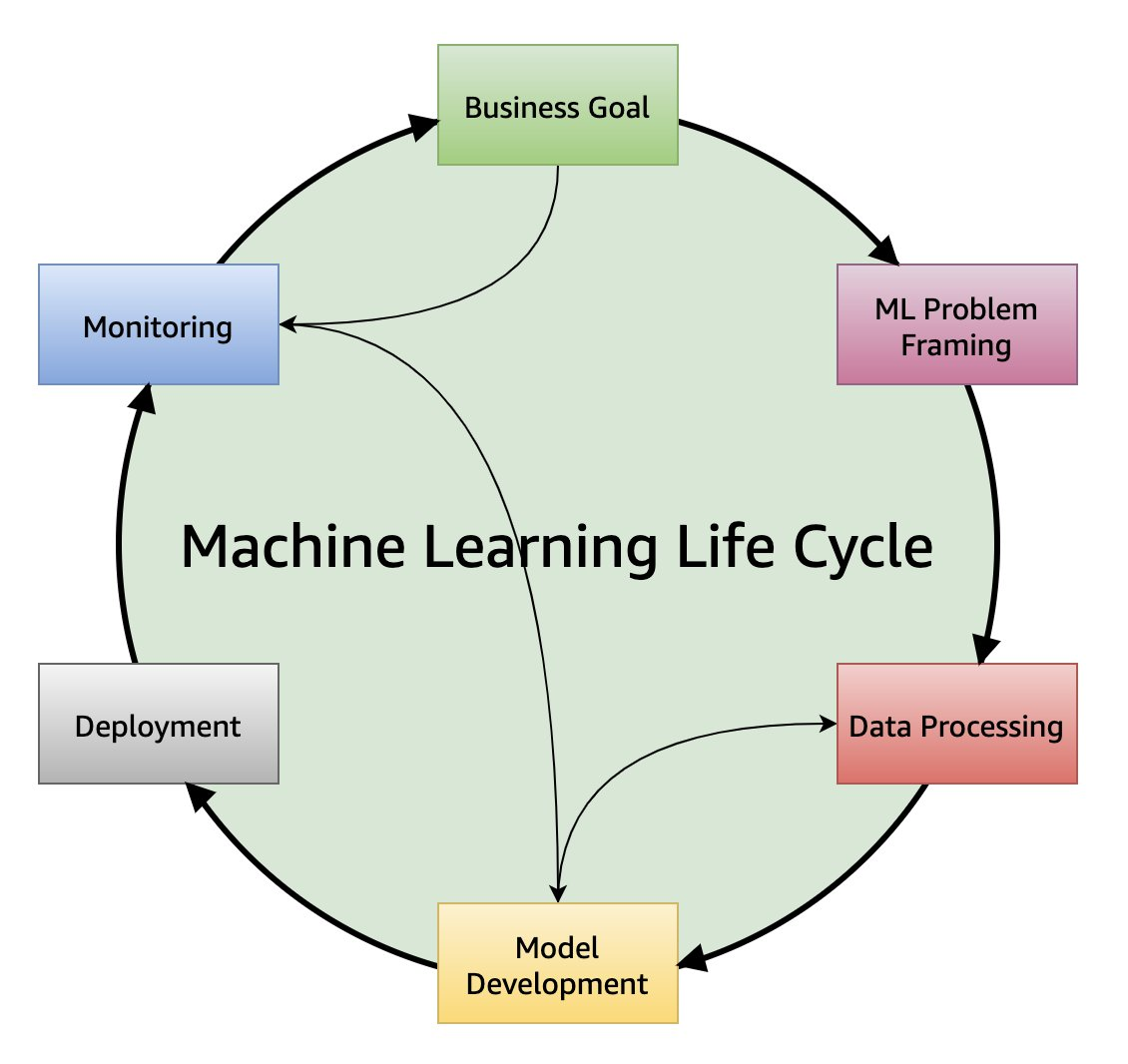
AWS Well-Architected machine learning lifecycle
| Phase | Goal | Example Activities / Tools |
|---|---|---|
| 1 · Problem Definition & Data Collection | Frame the problem, identify KPIs, collect and validate raw data | AWS Glue, S3, DVC, OpenSearch, Data Wrangler |
| 2 · Data Preparation & Feature Engineering | Transform raw data into clean, structured features | SageMaker Feature Store, Feast, Pandas Pipelines |
| 3 · Model Development & Experimentation | Build and train candidate models, track experiments | SageMaker Studio Lab, SageMaker Experiments, MLflow, Weights & Biases |
| 4 · Model Evaluation & Validation | Evaluate accuracy, bias, explainability, and robustness | Amazon SageMaker Clarify, Deepchecks |
| 5 · Deployment & Inference | Package and deploy model endpoints or batch jobs | SageMaker Endpoints, FastAPI, LitServe, EKS on Fargate |
| 6 · Monitoring & Feedback Loop | Track performance and drift, trigger retraining | SageMaker Model Monitor, Evidently, Prometheus, Deepchecks, |
These phases collectively form what AWS and Databricks describe as the ML Lifecycle—a cyclic process where every iteration improves the model’s reliability and the organization’s learning capability.
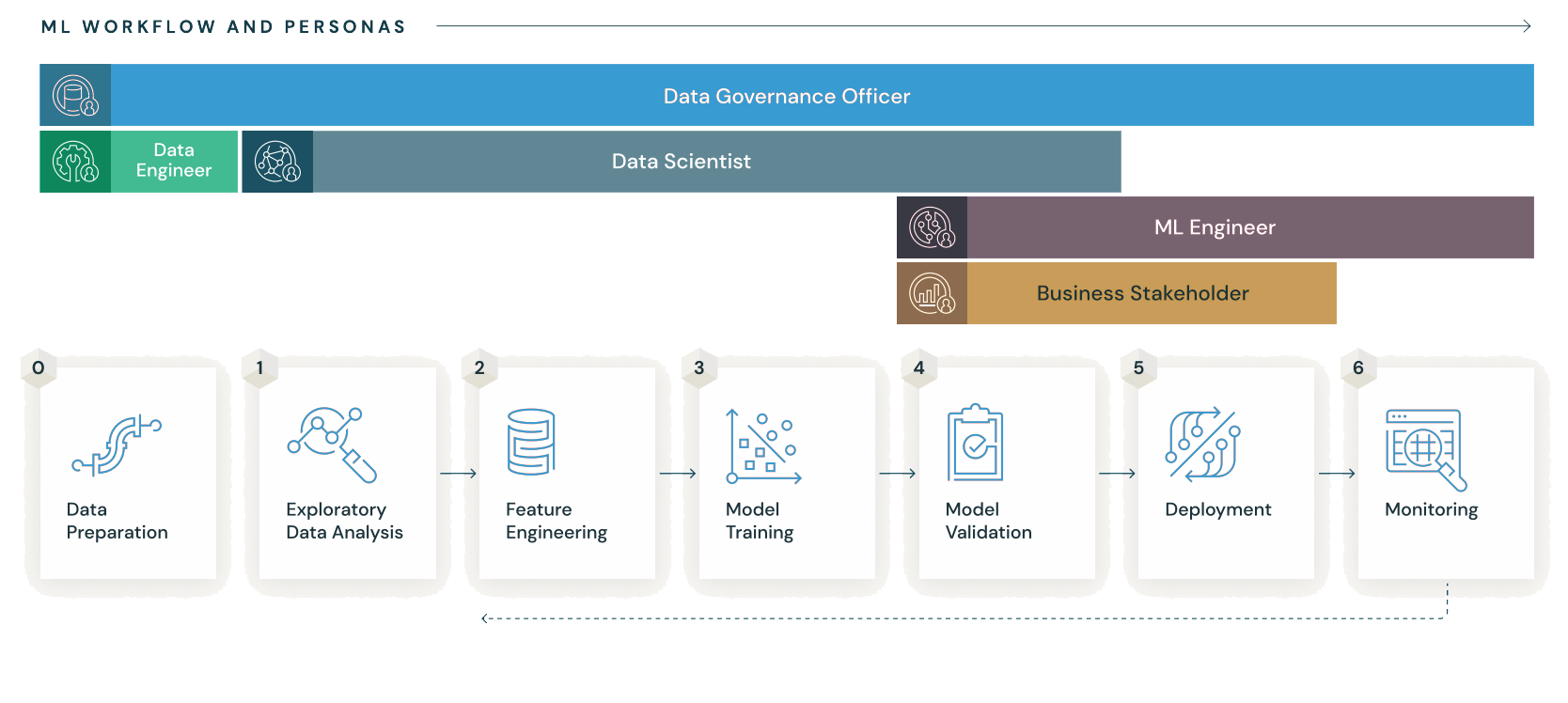
This continuous loop aligns with AWS MLOps best practices in SageMaker MLOps Guidelines and Databricks MLOps
The MLOps Lifecycle Loop
An MLOps architecture turns this lifecycle into structured systems.
Each phase maps to a corresponding architectural layer — transforming theory into design.
| Layer | Function | Examples (AWS & Open Source) |
|---|---|---|
| Data Layer | Ingest, clean, catalog, and store | AWS Glue, S3, Delta Lake |
| Feature Layer | Compute, store, and share features | SageMaker Feature Store, Feast |
| Experiment Layer | Train models and record experiments | SageMaker Experiments, MLflow |
| Model Registry Layer | Track and approve model versions | SageMaker Model Registry |
| Deployment Layer | Automate CI/CD & endpoint provisioning | SageMaker Pipelines, Argo CD |
| Monitoring Layer | Observe model behavior and drift | SageMaker Model Monitor, Prometheus |
A well-architected system doesn’t just connect components — it defines clear boundaries between them, making change safe and predictable.
Modern MLOps can be visualized as a continuous loop connecting development and operations:
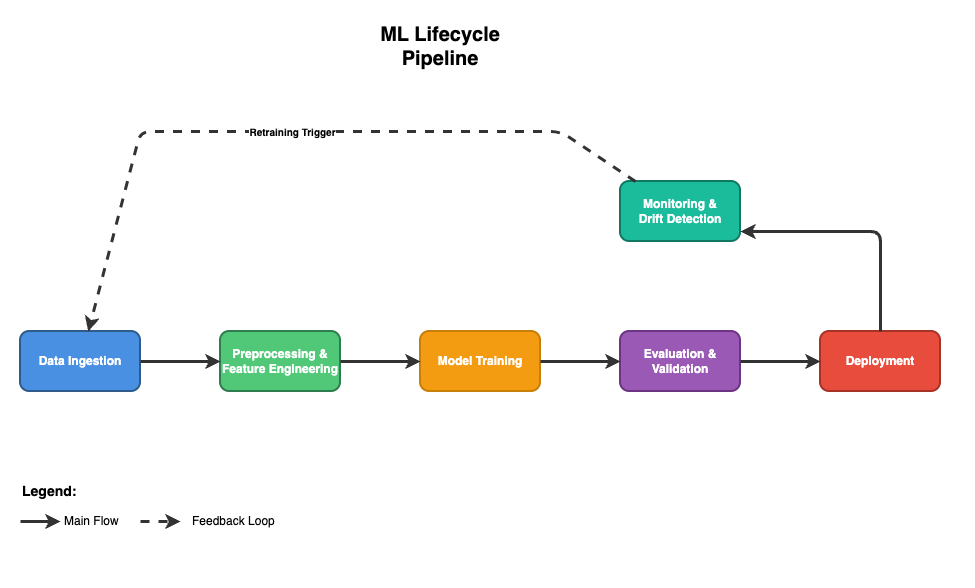
This loop is powered by CI/CD/CT principles:
- Continuous Integration (CI) integrates new code and data changes.
- Continuous Delivery (CD) automates deployment into test and prod environments.
- Continuous Training (CT) ensures models retrain automatically as data or performance metrics drift.
AWS SageMaker MLOps Guidelines detail how to orchestrate these cycles using services such as SageMaker Pipelines, CodePipeline, and EventBridge for event-driven automation.
“A healthy MLOps system never stops moving. Data flows in, insight flows out, and learning flows back again.”
Governance and Traceability Hooks in MDLC
To build trustable AI systems, governance must be embedded throughout the lifecycle—not retrofitted at the end. A well-governed MLOps system aligns technical behavior with legal, ethical, and organizational standards.
Across industries, these controls map to global frameworks that share a single goal: make AI auditable without suffocating creativity.
| Control Area | Objective | Referenced Frameworks | Implementation Example |
|---|---|---|---|
| Data Lineage & Quality | Track dataset origins and transformations | ISO/IEC 27701, FAIR Data Principles | AWS Glue Data Catalog + Feature Store metadata |
| Model Explainability & Bias | Provide transparency in predictions | NIST AI RMF (Map/Measure) | SageMaker Clarify reports |
| Experiment Reproducibility | Ensure repeatable runs | ISO/IEC 5339 (MLOps Standard) | MLflow Tracking + versioned datasets |
| Deployment Security | Isolate production traffic | AWS WAF Operational Excellence Pillar | VPC, PrivateLink, KMS Encryption |
| Monitoring & Audit | Detect drift and log events | ISO/IEC 42001 AI Management | SageMaker Model Monitor + CloudTrail |
For regulated industries, frameworks like NIST AI RMF, ISO/IEC 42001, and EU AI Act recommend a Plan-Do-Check-Act loop—precisely what a mature MLOps pipeline embodies.
Example AWS Reference Architecture
AWS SageMaker Secure MLOps (GitHub sample) demonstrates how to build a multi-account, auditable MLOps foundation using infrastructure-as-code.
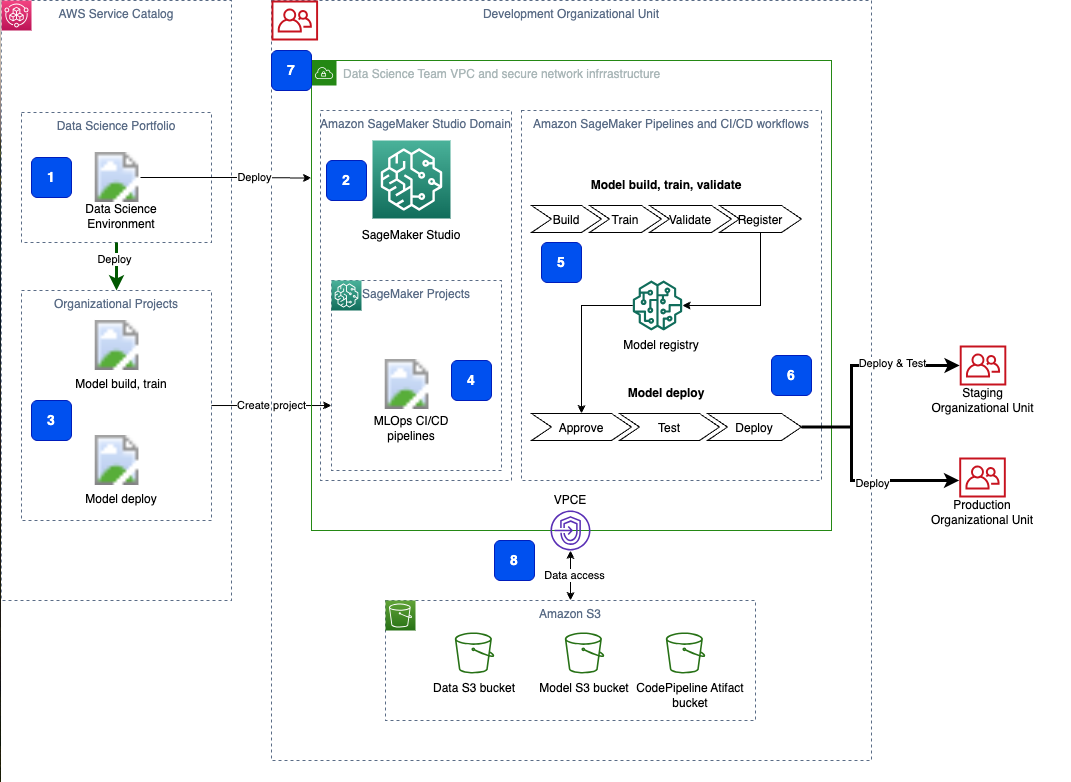
Flow:
- Data Layer: S3 + Glue manage ingestion and lineage.
- Training Layer: SageMaker Pipelines orchestrate preprocessing, training, and evaluation.
- Registry Layer: Model versions stored and approved in SageMaker Model Registry.
- Deployment Layer: CodePipeline or Argo CD handles staged rollouts.
- Monitoring Layer: Model Monitor + CloudTrail + EventBridge enable drift detection and retraining.
🧭 The MLOps Maturity Model — Building the Roadmap for Scale
MLOps maturity isn’t about owning the most tools—it’s about delivering machine-learning value reliably, safely, and at increasing velocity.
Every organization starts somewhere, but not everyone knows where they actually are or what to build next.
The MLOps Maturity Model below defines four practical levels (1 – 4) that map directly to your team’s current capabilities and future investments.
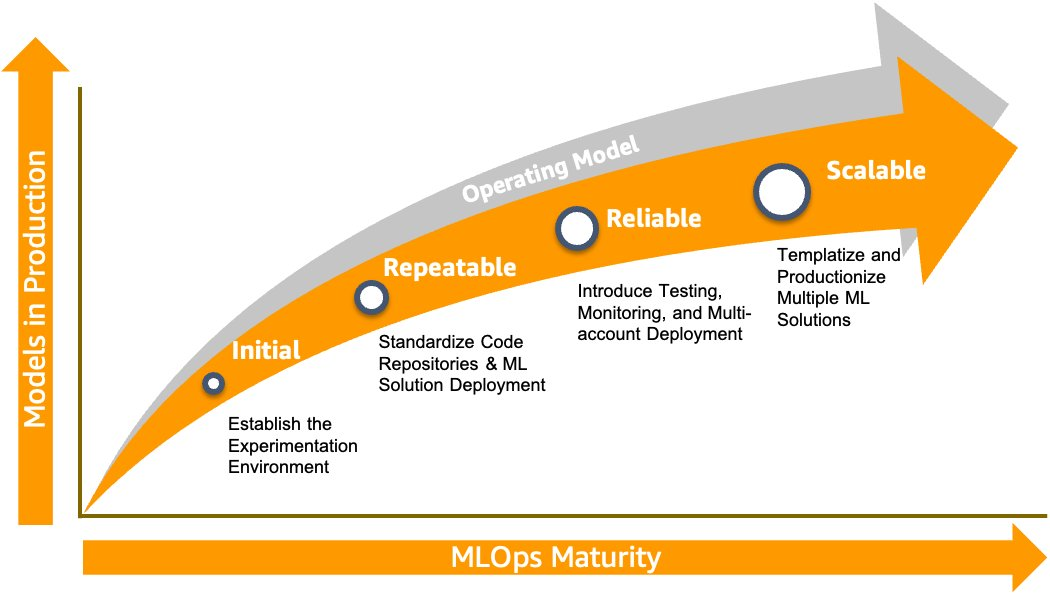
Maturity Levels at a Glance
| Level | Name | Key Characteristics | Typical Technologies / Practices |
|---|---|---|---|
| 1 – Initial | Experimentation | Data scientists work in notebooks, building models ad-hoc, minimal versioning or tracking | Amazon SageMaker Studio for experimentation, notebooks, manual scripts. |
| 2 – Repeatable | Automated Workflows | ML pipelines created: data ingest → train → register; version control introduced. | Amazon SageMaker Pipelines, Amazon SageMaker Model Registry, CI/CD flows. |
| 3 – Reliable | Pre-Production & Testing | Models are deployed first in staging, full testing introduced (integration, performance, ML tests). | Multi-account setup, automatic tests, manual approvals, blue/green or canary rollout. |
| 4 – Scalable | Enterprise-Scale | Platform supports many teams, reuse, templating of pipelines, self-service for data science. | Template repositories, multi-team environment, automation of account creation, enterprise governance. |
Progression Roadmap and What to Build First
Level 1 — Initial (Ad-hoc and Experimental)
Every journey begins in the notebooks — data scientists experimenting with models, datasets, and hyperparameters in isolation.
At this stage, models live in personal environments with little version control, documentation, or reproducibility.
There’s excitement, but also fragility: results can’t easily be reproduced or deployed.
Key Characteristics:
- Ad-hoc experimentation with minimal process or governance
- Limited reproducibility or shared repositories
- Manual training, evaluation, and deployment
- Metrics tracked in spreadsheets or notebooks
Tools & Practices
- Experimentation & Tracking: MLflow Tracking, Weights & Biases, Comet
- Data Storage: Amazon S3, Google Cloud Storage, Azure Blob Storage
- Version Control: GitHub, GitLab, Bitbucket
- Containerization: Docker for portable environments
Strategic Outcome:
🔹 Curiosity becomes capability — ML research starts to look like engineering.
Level 2 — Repeatable (Automating the Basics)
Once experimentation becomes repeatable, organizations begin introducing pipelines and reproducibility.
Training, evaluation, and deployment are now encoded as automated workflows, eliminating the fragile hand-offs between teams.
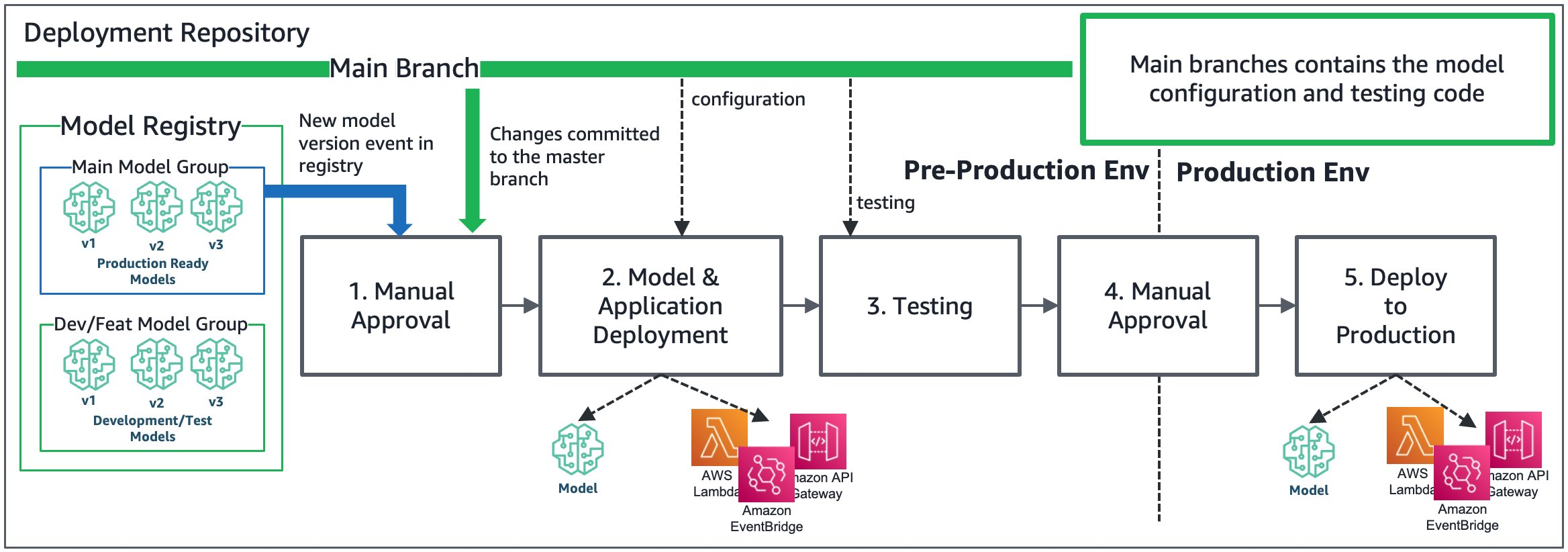
CI/CD pipeline to promote a model and the infrastructure to trigger the model endpoint, such as API Gateway, Lambda functions, and EventBridge
Key Characteristics:
- CI/CD for ML introduced (training → evaluation → registration → deployment)
- Experiment tracking and metadata logging standardized
- Basic governance introduced — approvals, artifact versioning, and rollback capability
- Teams start building one model pipeline that works end-to-end
Tools & Practices
- Workflow Orchestration: Apache Airflow, Argo Workflows, Prefect, Dagster
- Model Registry: MLflow Model Registry, Vertex AI Model Registry, SageMaker Model Registry
- Data Versioning: DVC, LakeFS, Delta Lake
- Testing & Validation: Great Expectations, Deepchecks
- CI/CD: GitHub Actions, GitLab CI, Jenkins, AWS CodePipeline
Strategic Outcome:
🔹 ML becomes repeatable, measurable, and reliable enough to earn a production slot.
Level 3 — Reliable (Testing, Monitoring, and Multi-Account Governance)
At this level, ML systems mature into trusted production workflows.
Pipelines are versioned, monitored, and tested continuously.
Governance shifts from manual oversight to automated enforcement, ensuring reproducibility, compliance, and reliability across environments.
Key Characteristics:
- Multi-account structure separating dev, staging, and prod
- Automated testing: integration, performance, and drift detection
- Central model registry and feature store
- Governance policies for audit, access control, and approval workflows
Tools & Practices
- Monitoring & Drift Detection: Evidently AI, WhyLabs, SageMaker Model Monitor, Arize AI
- Feature Store: Feast, Hopsworks, Vertex AI Feature Store, SageMaker Feature Store
- Governance & Audit: Neptune.ai Lineage, DataHub, OpenMetadata
- Security & Access Control: IAM (Cloud), OPA – Open Policy Agent, Vault
- Monitoring Stack: Prometheus + Grafana, OpenTelemetry
Strategic Outcome:
🔹 ML evolves from “something we launch” into “something we can trust.”
Level 4 — Scalable (Enterprise-Grade MLOps)
At the final stage, MLOps transforms into a platform function—serving multiple teams, domains, and model types.
Self-service pipelines, governance frameworks, and cost optimization come standard.
The focus shifts from deploying models to operating intelligence as infrastructure.
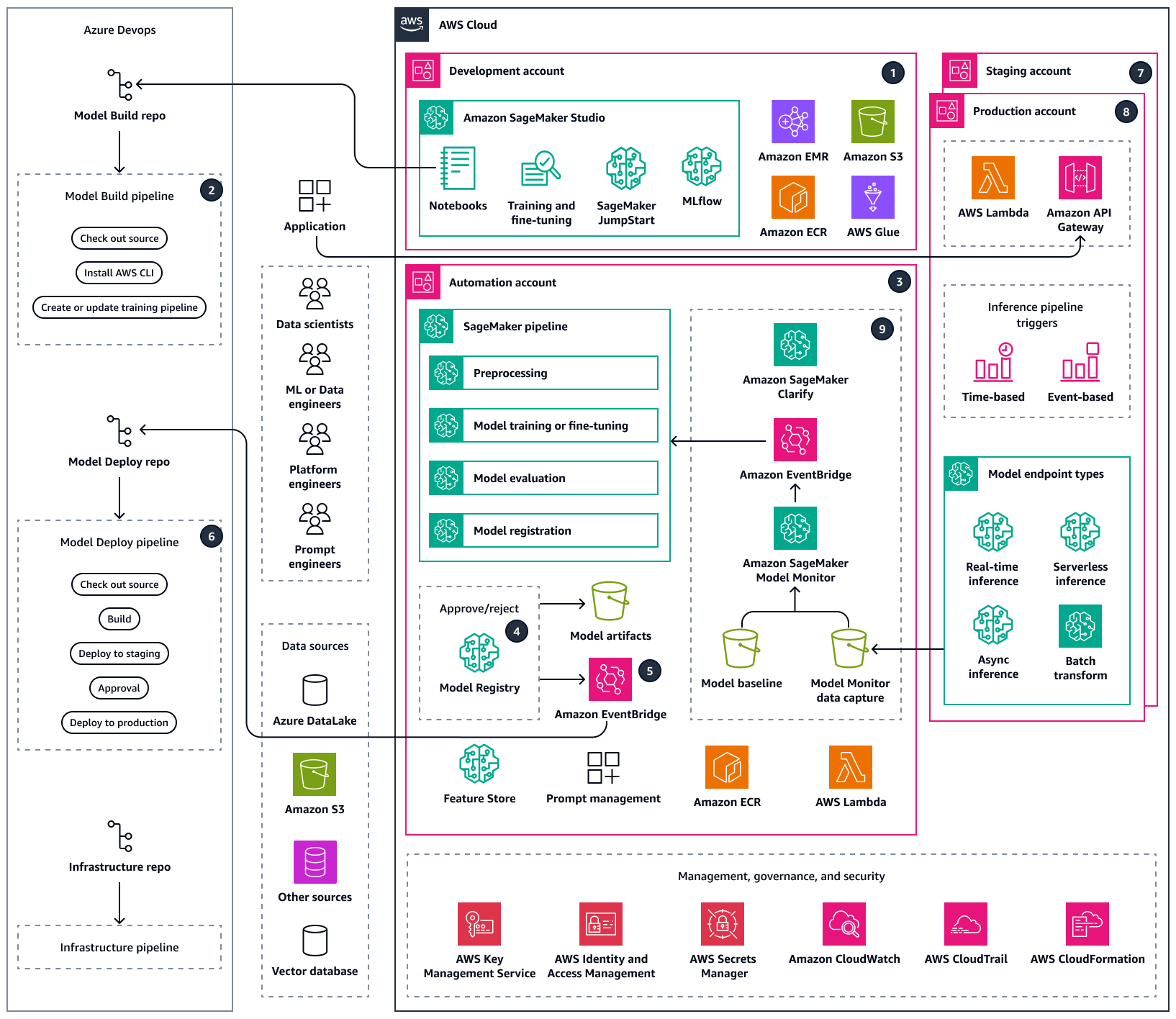
Sample MLOps workflow by using Amazon SageMaker AI and Azure DevOps
Key Characteristics:
- Multi-team, multi-region architecture with reusable templates
- Unified governance and policy automation
- Cost-aware orchestration (optimize GPU/CPU usage, spot training)
- Integration with business KPIs for impact-based retraining decisions
- Automated account provisioning and security baseline enforcement
Tools & Practices
- Platform Frameworks: Kubeflow, Flyte, Metaflow, SageMaker Projects
- Serving & Routing: KServe, Seldon Core, BentoML, Ray Serve
- Observability & Cost: Finout, Kubecost
- Governance & Templates: Terraform, Pulumi, AWS Service Catalog, Azure ML Registries
- LLM Ops & Evaluation: Ragas, TruLens, PromptLayer, LangFuse
Strategic Outcome:
🔹 ML becomes a core product capability—a living system that learns, scales, and delivers measurable value enterprise-wide.
Measuring ROI and Building the Business Case
📈 ROI and Organizational Growth
| Metric | Level 1 → 2 | Level 2 → 3 | Level 3 → 4 |
|---|---|---|---|
| Time to Production | Weeks → Days | Days → Hours | Hours → Minutes |
| Deployment Frequency | Monthly | Weekly | Continuous |
| Incidents per Release | High | Low | Predictive |
| Models in Production | 1–5 | 10 + | 100 + |
| Team Evolution | DS-only | ML Engineer + DevOps | Dedicated Platform Team |
Template Tip:
Build your internal business case using tangible metrics: time-to-deploy, incident cost, and data-scientist hours saved. A concise ROI deck usually unlocks executive sponsorship faster than a tool comparison.
ROI Template
# Business Case: MLOps Maturity Progression (Level X → Level Y)
## Executive Summary
We propose investing $_____ over ____ months to progress from MLOps Maturity Level X to Level Y. This will reduce time-to-market by ___%, reduce incidents by ___%, and enable ____ additional models in production annually.
**Expected ROI**: ____x over 3 years
**Payback Period**: ____ months
## Current State (Level X)
- Time to production: ____ weeks
- Models in production: ____
- Incidents per month: ____
- Engineering time on manual tasks: ____% of capacity
- Annual cost of incidents: $_____
## Proposed Future State (Level Y)
- Time to production: ____ days/hours
- Models in production: ____ (increase of _____%)
- Incidents per month: ____ (reduction of _____%)
- Engineering time on manual tasks: ____% (freed up _____% capacity)
- Annual cost of incidents: $_____ (reduction of $_______)
## Investment Required
### People
- ML Platform Engineers: ____ FTEs at $_____ each = $_____
- DevOps/SRE Engineers: ____ FTEs at $_____ = $_____
- Training for existing team: $_____ (external courses, certifications)
- **Total People Cost**: $_____
### Technology
- Cloud infrastructure: $_____ per year
- Tooling licenses: $_____ per year (list tools)
- Professional services / consulting: $_____
- **Total Technology Cost**: $_____
### Total Investment
- Year 1: $_____ (implementation)
- Year 2: $_____ (operations)
- Year 3: $_____ (operations)
- **3-Year Total**: $_____
## Expected Benefits
### Quantifiable Benefits
**Increased Velocity**:
- Reduced time-to-market: From ____ weeks to ____ days
- Additional models shipped per year: ____ → ____
- Value per model: $_____ (revenue/cost savings)
- **Annual Benefit**: $_____ × ____ models = $_____
**Reduced Incidents**:
- Current incident cost: ____ incidents/month × $_____ per incident = $_____/year
- Future incident cost (reduced by ____%): $_____/year
- **Annual Savings**: $_____
**Increased Productivity**:
- Engineering time freed up: _____% of ____ FTEs = ____ FTE-equivalents
- Value of freed capacity: ____ FTEs × $_____ = $_____
- **Annual Benefit**: $_____
**Total Quantifiable Benefit (Annual)**: $_____
**3-Year Benefit**: $_____
### Qualitative Benefits
- Improved data scientist satisfaction and retention
- Faster experimentation and innovation
- Better governance and compliance posture
- Competitive advantage in ML capabilities
## ROI Calculation
**3-Year Investment**: $_____
**3-Year Benefit**: $_____
**Net Benefit**: $_____ - $_____ = $_____
**ROI**: (Net Benefit / Investment) × 100 = _____%
**Payback Period**: (____ months)
## Risk Analysis
| Risk | Impact | Probability | Mitigation |
|------|--------|------------|------------|
| Team doesn't adopt new tools | High | Medium | Involve team in selection, provide training, champions program |
| Technology doesn't meet requirements | High | Low | POC validation before full rollout |
| Cost overruns | Medium | Medium | Phased rollout, budget buffers, regular cost reviews |
| Talent acquisition challenges | Medium | Medium | Start recruiting early, consider contractors/consultants |
## Phased Rollout Plan
### Phase 1 (Months 1-3): Foundation
- Hire platform engineers
- Set up core infrastructure
- POC with 1-2 pipelines
- **Investment**: $_____
- **Quick Wins**: Automate 1 model, reduce deployment time by 50%
### Phase 2 (Months 4-6): Scale
- Migrate 5-10 models to new platform
- Roll out to first data science team
- Establish best practices
- **Investment**: $_____
- **Quick Wins**: 5-10 models automated, 70% deployment time reduction
### Phase 3 (Months 7-12): Optimize
- Migrate all models
- Advanced features (drift detection, A/B testing)
- Self-service platform
- **Investment**: $_____
- **Quick Wins**: All models on platform, full ROI realized
## Success Metrics
### 6-Month Checkpoint
- [ ] ____ models on new platform
- [ ] Deployment time reduced to ____ days
- [ ] ____ incidents (down from ____)
- [ ] Team satisfaction: 4/5 average
### 12-Month Checkpoint
- [ ] ____ models on new platform
- [ ] Deployment time: ____ hours
- [ ] ____ incidents (down ___%)
- [ ] ROI breakeven achieved
## Recommendation
**APPROVE / DEFER / REJECT**
We recommend APPROVAL based on:
- Strong ROI (____x over 3 years)
- Fast payback (____ months)
- Strategic necessity (competitors are investing)
- Risk-mitigated approach (phased rollout)Anti-Patterns to Avoid
- 🚫 “Boiling the Ocean” — Don’t build Level 4 features before nailing Level 1.
- 🚫 “Tools Before Problems” — Choose tech only when you feel the pain it solves.
- 🚫 “Platform in a Vacuum” — Co-create with data scientists; adoption is success.
- 🚫 “Copying Big Tech” — Google’s Level 4 blueprint doesn’t fit a team of five.
Your Next Step
- Assess honestly — where are you today?
- The AWS MLOps checklist is a workable checklist that you can use at any phase in your machine learning (ML) project
- Target the next level, not the final one.
- Invest in people before platforms.
- Define ROI and metrics upfront.
- Build foundations that scale with you.
“Maturity isn’t measured by tools deployed—it’s measured by how confidently your models deliver value, again and again.”
🧭 Conclusion & Final Takeaway
Building MLOps is as much about designing for learning and compliance as it is about automation.
A well-architected pipeline enables trustworthy AI delivery that can adapt, scale, and govern itself in production.
“The most powerful pipelines are the ones that learn, adapt, and govern themselves.
MLOps is no longer an ops function—it’s the operating system of modern AI.”
🧩 Multi-Part Series Roadmap
🧭 This article is part of the series:
Part 1 – From Model Development to Scalable, Compliant Operations
Part 2 – Building an MLOps Pipeline Step-by-Step
Part 3 – Designing Adaptive and Resilient MLOps Pipelines

Leave a comment