Modular by default, governed by design, and ready to evolve.

“Rigid pipelines break with change. Adaptive pipelines learn from it.”
🧭 This article is part of the series:
Part 1 – From Model Development to Scalable, Compliant Operations
Part 2 – Building an MLOps Pipeline Step-by-Step
Part 3 – Designing Adaptive and Resilient MLOps Pipelines
Why Adaptability Matters
ML systems are non-stationary: data shifts, objectives evolve, and tooling changes. The AI landscape is evolving faster than any discipline we’ve seen. A pipeline that can’t adapt will either stall innovation or leak risk.
But the key isn’t just adaptability—it’s architecting for adaptability.
The challenge in fast-moving AI environments is to operate with disciplined evaluation instead of reactive adoption. The solution isn’t constant reinvention; it’s building a stable, extensible platform that lets us test new models in isolation, benchmark their cost, latency, and quality, and then promote them to production once validated.
The Three-Layer Approach to Adaptive Architecture
I approach adaptability in three layers:
1. Foundation: Build a governed, model-agnostic platform layer—so new models or frameworks can plug in without rewriting pipelines. This gives us stability at the base.
2. Enablement: Create automated benchmarking and cost-performance telemetry—so as new models appear, we can evaluate them objectively, not anecdotally. Make new model adoption a data-driven decision, not a hype-driven one.
3. Evolution: Maintain a continuous improvement loop—retraining, validation, and deployment governed through MLOps pipelines.
The outcome is a system that doesn’t need to be rebuilt every 6 months—it evolves naturally as the ecosystem changes.
- Industry signal: Flexible, reusable components accelerate iteration and reduce fragility (F-Mind).
- Governance signal: Adaptive design is easier to control: you attach policies to interfaces, not to bespoke code paths (see AWS Well-Architected, NIST AI RMF).
“Architect for adaptability, not for permanence.” “Stability comes from modularity and observability.”
The Five “Ilities” — Design to Operate at Scale
If flexibility is the foundation, the Five Ilities are the moral code of resilient design.
They don’t just describe how systems behave—they describe how they learn.
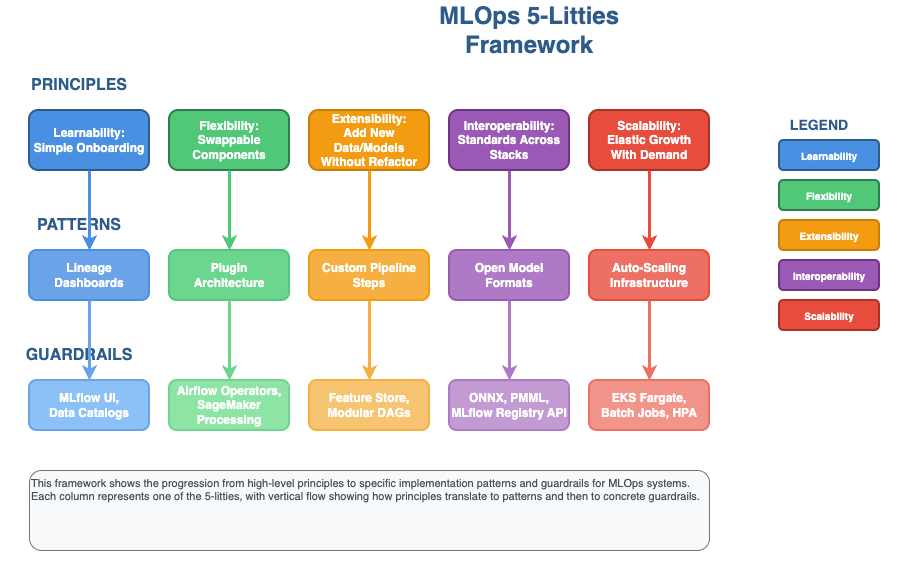
| Principle | Design Intent | Concrete Tactics | Useful Tools / Formats |
|---|---|---|---|
| Learnability (means your system teaches itself—and its users—over time.) | Make pipelines easy to understand, reproduce, and teach | Uniform folder structure, run metadata, notebooks→scripts handoff, model cards | MLflow Tracking/Registry (https://mlflow.org), lineage UIs, model cards |
| Flexibility (allows you to adapt quickly without rewriting the foundation) | Swap tech with minimal blast radius | Containerized steps, strict interfaces, parameterized configs | Kubernetes, Helm/Kustomize, Airflow/Kubeflow, SageMaker Pipelines |
| Extendibility (Reusable interfaces and clearly defined input/output schemas make this possible) | Add new data types/models/checks without refactor | Plug-points (post-train/deploy), adapter modules, feature connectors | Plugin registries, Clarify, custom evaluators |
| Interoperability (It’s the bridge between teams, tools, and even clouds) | Move artifacts across stacks and teams | Standard model & data formats, API contracts, metadata schemas | ONNX (https://onnx.ai), Parquet/Arrow, MLflow Model/Registry APIs |
| Scalability (As data and users grow, the pipeline breathes with them) | Scale users, models, and traffic elastically | HPA/KEDA, multi-tenant namespaces/accounts, event-driven CT | EKS + HPA/KEDA (https://keda.sh), EventBridge/Lambda, autoscaled endpoints |
Interface Contracts (where resilience is born)
Every adaptive system needs rules of engagement. In MLOps, those rules are written as interface contracts—the promises one component makes to another.
They’re the glue that keeps a fast-moving architecture from turning into chaos.
A data pipeline can change formats, but as long as the output schema is validated in CI, the downstream training job never notices.
A model can change frameworks, but if it still exposes a standard predict() method, the serving layer stays untouched.
These invisible agreements are what make change safe.
Lock the boundaries, not the internals.
- Data I/O: Parquet/Arrow + schema in source control; contracts validated in CI.
- Model Package: Use standard formats (e.g., ONNX) or MLflow flavors; include a predict() contract and signature.
- Metrics & Telemetry: Adopt OpenTelemetry or Prometheus conventions for latency, throughput, and custom model metrics.
- Registry Metadata: Minimal required fields: dataset hash, code commit, hyperparams, eval metrics, compliance flags, owner.
- Serving API: REST/gRPC spec with versioned endpoints; include request/response schema and error contract.
the smaller the contract surface, the easier the upgrades.
Governance that Scales (WAF + NIST + ISO)
Adaptive pipelines still need strong guardrails. The goal is to bring order to the chaos of AI tooling via benchmarking, model routing, and governed onboarding.
This isn’t about chasing the latest model—it’s about building a mechanism to evaluate the newest model safely. The goal is to stay informed, not impulsive—adapt fast, but through a structured process.
Embed governance controls into the pipeline fabric:
- Operational Excellence (AWS WAF): IaC for infra changes; PR-gated environment repos; automated checks on policy drift.
- Security (AWS WAF): Least-privilege IAM/IRSA, KMS encryption, VPC endpoints/PrivateLink; secrets via External Secrets → AWS Secrets Manager.
- Reliability: Health/readiness probes, autoscaling, multi-AZ; rollbacks/canaries by default.
- Performance & Cost: SLOs & autoscaling rules; right-size instances; idle culls; batch where possible.
- AI Risk (NIST AI RMF): Tie risks to lifecycle checkpoints: bias/explainability at eval; monitoring thresholds in prod. Evaluate new capabilities before integrating them—test models in isolation with rigorous benchmarking.
- AI Management (ISO/IEC 42001): Treat the pipeline as a managed process (Plan-Do-Check-Act) with documented roles, records, and audits.
A pipeline that internalizes these principles doesn’t need external policing—it self-governs, flagging when data, performance, or policy drift threatens its integrity.
“The field moves fast—so our systems must evolve safely, not reactively.”
Example: An Adaptive & Resilient Pipeline Template
The diagram below illustrates how these principles come together into a cohesive pipeline architecture that embodies the three-layer approach to adaptability.

The Three Layers in Action
Layer 1: Foundation (Blue) – The model-agnostic platform layer establishes interface contracts that lock boundaries while keeping internals flexible:
- Data I/O contracts with schema validation (Parquet/Arrow formats)
- Model package contracts (ONNX/MLflow formats)
- Metrics contracts (OpenTelemetry/Prometheus)
- Serving API contracts (REST/gRPC versioned endpoints)
- All steps containerized for portability and isolation (Kubernetes/Helm)
Layer 2: Enablement (Orange) – Automated benchmarking transforms model adoption from hype-driven to data-driven:
- Cost-performance telemetry tracks latency, accuracy, and operational costs
- Objective model evaluation compares candidates against production baselines
- Benchmark new models in isolation before integration
- Evaluation gates enforce threshold-based promotion
Layer 3: Evolution (Green) – Continuous improvement loops ensure the system learns and adapts:
- Drift detection monitors data and model drift in production (Evidently/Deepchecks)
- Retrain triggers (automated or manual) initiate the CT pipeline (Argo Workflows)
- Data and model lineage provide full audit trails
- Governance controls automate policy enforcement
Core Pipeline Flow
9 containerized steps form the backbone:
- Ingest & Validate – Data quality checks with schema contracts
- Feature Build – Feature engineering (Feast/SageMaker Feature Store)
- Train – Model training with trainer-agnostic containers (XGBoost/LightGBM/Transformers)
- Evaluate – Task-specific metrics + bias checks (Clarify/AIF360)
- Explain – Generate explainability artifacts (SHAP/Clarify)
- Register – MLflow/SageMaker Model Registry with full lineage
- Promote – Governed stage promotion through evaluation gates
- Deploy – Progressive deployment (canary/blue-green/shadow)
- Monitor – Drift detection (Evidently/Deepchecks) with threshold alerts
Deployment Options
The pipeline supports multiple deployment patterns:
- FastAPI Microservices: Helm + HPA + Argo Rollouts for canary deployments
- KServe InferenceService: Declarative serving with Triton/TorchServe
- Progressive Delivery: All deployments use canary, blue-green, or shadow strategies
Storage & Registry
- S3 Object Storage: Parquet + JSON schema for data, artifacts versioned and immutable
- MLflow Registry: Params, metrics, artifacts, and lineage connections
The outcome? A system that doesn’t need to be rebuilt every 6 months—it evolves naturally as the ecosystem changes. This is adaptability through design, not through chaos
Progressive Delivery for Models (canary/blue-green)
Once a model is ready for the real world, deployment becomes less about technology and more about risk management.
Modern MLOps teams borrow from DevOps playbooks:
- Blue/Green: Spin a full green stack; shift 100% on pass; rollback instantly.
- Canary: 5% → 25% → 50% → 100% with automated analysis (p95 latency, error rate, drift score).
- Shadow: Route a copy of traffic to the new model; compare responses offline before exposure.
Tools: Argo Rollouts, service mesh analysis, or SageMaker endpoint variants for multi-variant testing.
Observability by Design
True observability means every layer of the system can see itself and respond before problems escalate.
You can’t govern what you can’t see.
- System Metrics: Prometheus + Grafana dashboards (RED/USE) – these track latency, throughput, and resource usage.
- Model Metrics: Accuracy, calibration, drift, data quality (Evidently/Deepchecks).
- Logs & Traces: Structured logs; OpenTelemetry where feasible.
- Model Monitor: If using SageMaker endpoints, wire SageMaker Model Monitor for schema changes and drift.
- Feedback Store: Capture outcomes/labels to close the CT loop.
Observability isn’t about flooding dashboards with numbers; it’s about clarity.
It lets you spot a drifting model before it harms trust, or a scaling bottleneck before it hurts performance.
More importantly, it transforms monitoring from a reactive checklist into a proactive dialogue between people and machines.
Conclusion: Systems That Learn to Last
Every “ility” we explored—learnability, flexibility, extendibility, interoperability, scalability—adds a new layer of muscle and memory. Together, they make the system self-aware enough to change responsibly without breaking its core.
- Faster onboarding (learnability): consistent templates and rich metadata.
- Lower coupling (flexibility): swap parts without retesting the world.
- Add capabilities quickly (extendibility): plug-in modules and post-deploy hooks.
- Cross-stack reuse (interoperability): standard formats and APIs.
- Elastic growth (scalability): autoscaling, queue-aware batch, multi-tenant isolation.
Flexibility lets you react to the unknown. Reusability and extensibility turn today’s experiment into tomorrow’s standard. Interoperability connects people and platforms. Scalability ensures your architecture can breathe as your ambitions grow. And observability binds them all together, giving your pipeline eyes, ears, and a voice.
Governance, once seen as a constraint, becomes the narrative thread that keeps everything coherent. It tells the story of how every model was built, what data it saw, who approved it, and when it learned to do better.
The Adaptability Mindset
Building resilient MLOps pipelines requires embracing adaptability through design, not through chaos:
- Don’t chase maturity like the hyperscalers—build a platform that’s resilient to change so you can move fast responsibly, even when the tools shift underneath you.
- Focus on codifying the right foundations—data lineage, orchestration patterns, and automated governance—so new capabilities can slot in with minimal disruption.
- Start small, automate rigorously, and scale through reuse.
The approach isn’t to chase the latest model, but to systematically evaluate new capabilities before integrating them. Build a stable, extensible platform that lets you test new models in isolation, benchmark their cost, latency, and quality, and then promote them to production once validated.
In other words: don’t advocate for “use the newest thing”—advocate for a framework that lets you evaluate the newest thing safely. That’s what makes adaptability sustainable.
As AI enters a new era—one defined by agentic systems and generative intelligence—these design habits will become even more essential.
“The goal isn’t to be static; it’s to be safely dynamic—a platform that learns as fast as the field itself.”

Leave a comment